Learning Goals
At the end of this Lesson you will be able to:
- Understand the basic concept of the Document Object Model (DOM).
- Use the document.getElementByID() method to access elements in a web page that have a unique ID.
- Use the document.getElementsByTagName() and document.querySelector() methods to access elements in a web page that have do not have a unique ID.
In this Lesson, you will meet the following term:
- DOM
In your javascript/exercises folder, create a new sub-folder named 4.
Save the exercise file below to this new javascript/exercises/4 sub-folder.
About the DOM
When a web browser accesses a web page – also known as an HTML document – it performs two operations. It:
- Displays (renders) the web page in the browser, using any links in the page to CSS, image, video font and other files.
- Creates a Document Object Model (DOM) of the web page that enables the page's content to be accessed and modified by JavaScript code. In effect, the DOM is an application programming interface (API).
Except in the following two instances, the HTML source code of a web page and the contents of its DOM will be the same:
- The browser has found HTML errors in the web page and has automatically fixed them when creating the DOM.
- The DOM has been modified by JavaScript, typically as the result of some user action such as clicking/tapping a button.
The DOM tree and nodes
Like the HTML web page it represents, a DOM has a tree-like structure. All items in the DOM are defined as nodes.
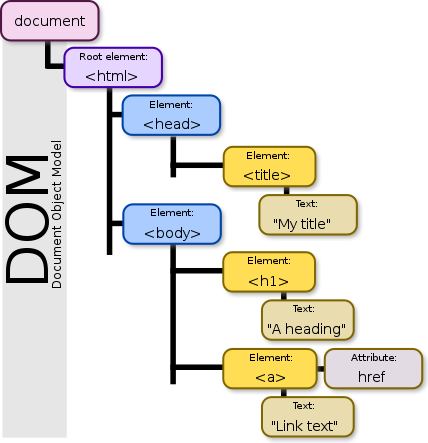
Node types
Every node in a DOM has a node type, accessed through the nodeType property. Three of the most common node types are as follows:
- Document node: The web page itself, which is the root or parent of all other nodes in the HTML file.
- Element node: An HTML element in a web page. Examples of element nodes would include <h1>Main Heading</h1> and <p>Hello world</p>.
- Text nodes: A text string. Typically, a text node is a child of a parent element node, such as the text nodes Main Heading and Hello worldabove. However, a text node can also exist outside an element node.
All DOM nodes, including the document node, have a nodeType property with a numeric value. See the table below.
Node |
Node Type |
|---|---|
document |
9 |
element |
3 |
attribute |
2 |
text |
1 |
You can see a full list of node types on the MDN website.
DOM terminology
To work with the DOM using JavaScript, it is important to understand a few key terms. Consider the HTML code below.
<p><a href="index.html">Home</a></p;>
- <p> ... </p> is the element
- a is the tag
- href is the attribute
- index.html is the attribute value
- Home is the text.
HTML element
Content in a web page that is marked up with an HTML tag. Most HTML elements (such as body, div, h1 and p) begin and end with an opening and closing tag pair. Others, such as link and img, are said to be self-closing. HTML elements may contain attributes with values.
A typical web page will contain many levels of elements nested inside one another in a parent-child relationship. Elements at the same level in a web page are said to be siblings.
Selecting an element with a unique id
Before you can work with an HTML element in JavaScript, you have to select it from the web page (document object) that contains it.s
JavaScript gives you two options to select a single element in a web page with a unique id:
- document.getElementById(ID). For example:
document.getElementById('userFirstName'); - document.querySelector(#ID): For example:
document.querySelector('#userLastName');
Both the method syntax and the target id are case-sensitive. Note that, with this second method, you must include a hash (#) character before the element id.
If there is more than one element with the same id in the web page (which there should not be!), the above two methods return the first element found. A null value is returned if no element with the target id exists in the web page.
Accessing the content of an element
After selecting an element in a web page, you can then access its content. Your two options are:
- innerText: This returns only the text content of the element, and excludes any HTML tags it may contain.
- innerHTML: This returns both the text content and any HTML tags within it.
If the target HTML element is an input field, you can access the field content with the value property:
Exercise 4.1: Accessing DIV elements
Write JS code that captures the string values in two DIVs and outputs the result to the web page and JavaScript Console.
The result should look as shown below.

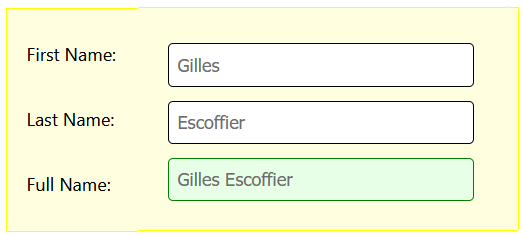
Exercise 4.2: Accessing form input elements
Write JS code that captures the string values in two forn input fields and outputs the result to the web page and JavaScript Console.
The result should look as shown below.
Selecting an element without a unique id
Not every element you want to access in a web page will have a unique id. JavaScript offers three other options in this situation:
- document.getElementsByTagName(index). For example:
document.getElementsByTagName('h3')[2];Note that the index numbers begin with 0. - document.querySelector(.class:nth-of-type(index): For example:
document.querySelector('.dark-text:nth-of-type(2)');Note that the index numbers begin with 1.
Exercise 4.3: Accessing elements by tag index
Within the page-content DIV of the exercises web page, select the third h3 heading and output the result to the JavaScript Console.
The result should look as shown below.

Exercise 4.4: Accessing elements by CSS class and indexed pseudo-class
Within the page-content DIV of the exercises web page, select the second p paragraph of text and output the result to the JavaScript Console.
The result should look as shown below.
